o3 from OpenAI Beats ARC-AGI
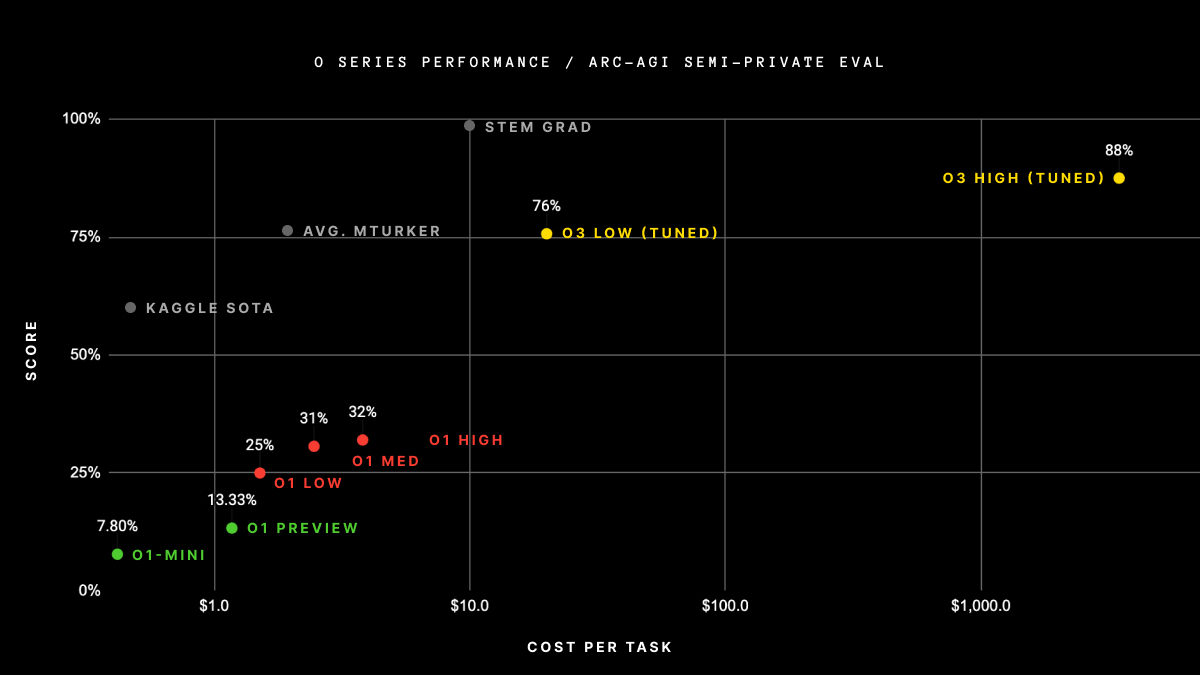
Table of Contents
OpenAI's new o3 system makes a breakthrough, scoring 75.7% on the ARC-AGI dataset! Giving higher compute to the o3 system makes it score 87.5%.
o3 system scores 75.7% on the semi-private set of the ARC-AGI dataset. With higher compute, it scores 87.5%. Image credit: 1
To understand just how wild it is, consider the scores of some other SotA LLMs:
- Gemini 1.5: 4.5%
- GPT4o: 5%
- Claude 3.5 Sonnet: 14%
Yes, it is wild!
But What is the ARC Benchmark?
ARC dataset is a collection of problems that are very easy for an average human to solve but have turned out to be nearly impossible to solve by traditional LLMs. As the official website puts it2:
It's easy for humans, but hard for AI.
Beating this benchmark is a necessary condition (though, not sufficient) before a system can be said to have achieved AGI.
A Puzzle From the ARC Dataset
Here is a sample puzzle from the ARC dataset:
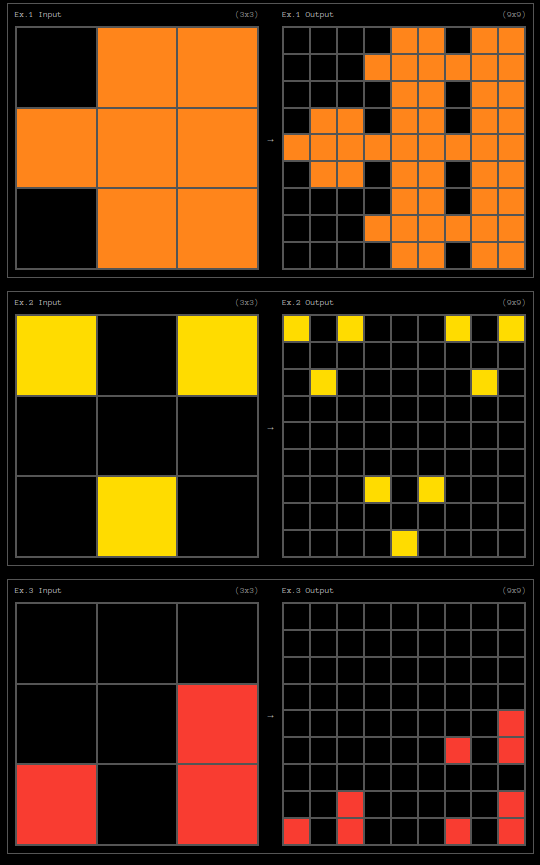

A sample puzzle from the ARC dataset. The left image shows the examples with inputs and outputs, and the right image shows the problem input. Find this puzzle here.
Each puzzle consists of multiple examples with input and output, followed by the problem input. Each input/output is just a 2D grid. There are some unique transformation rules that map the inputs to the output. The goal is to learn the rules on the fly and apply them to the problem input to figure out what the output grid will be. These rules are fairly straightforward for humans to figure out but turn out to be very difficult for an ML model. Can you guess the rules for the above examples? If yes, congratulations, you are human (hopefully)!
Since each puzzle in the ARC dataset has a different rule, a model can not rely on memorization or some template. A model has to reason through the inputs and learn the rules.
Answer to the Above Puzzle
The output grid results from repeating the input grid. Positions, where the input box was dark, remain dark for the output grid. We put the input grid as is on the positions where the input grid had colored boxes.
Does That Mean that the o3 System Has Achieved AGI?
The short answer is: No. ARC benchmark is not an acid test for AGI. Even though o3 scores 75.7% (which increases to 87.5% if we let it think for a longer time), it still fails on some ridiculously easy problems. The ARC AGI team is working on a second iteration of the benchmark, the ARC-AGI-2 benchmark. O3 may perform as low as 25% on the newer benchmark (even though the average human performance is still ~95%)^1. One thing we can say for sure is this: the success of the o3 system has forced many (me included) to change their views on if and when AGI is coming in the future.
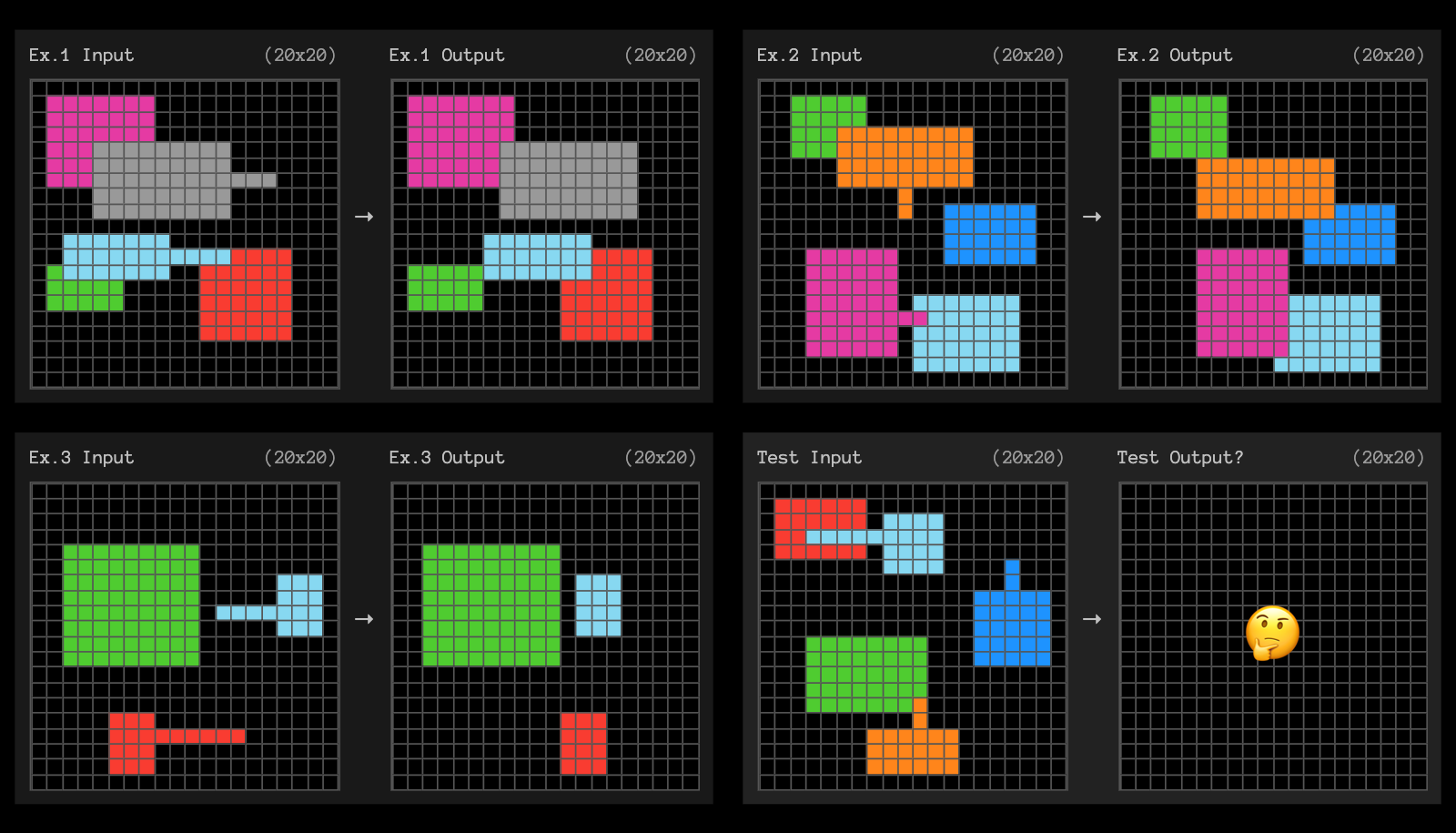
A relatively easy problem from the ARC-AGI dataset which the o3 system fails to solve. Can you solve the puzzle? Image credit: 1
What About Other Benchmarks?
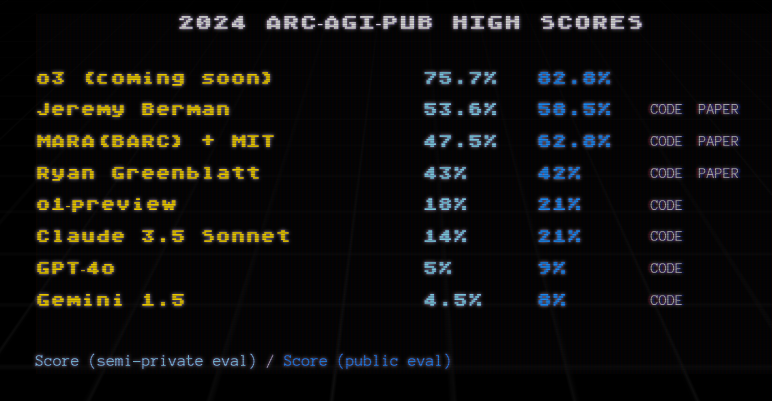
Well, o3 has triumphed over nearly all of the benchmarks. o3 has saturated benchmarks in software engineering, competition code, maths, PhD level science, and more. However, most of these benchmarks are already saturated, hence, it is beating the ARC benchmark that makes o3 truly special.
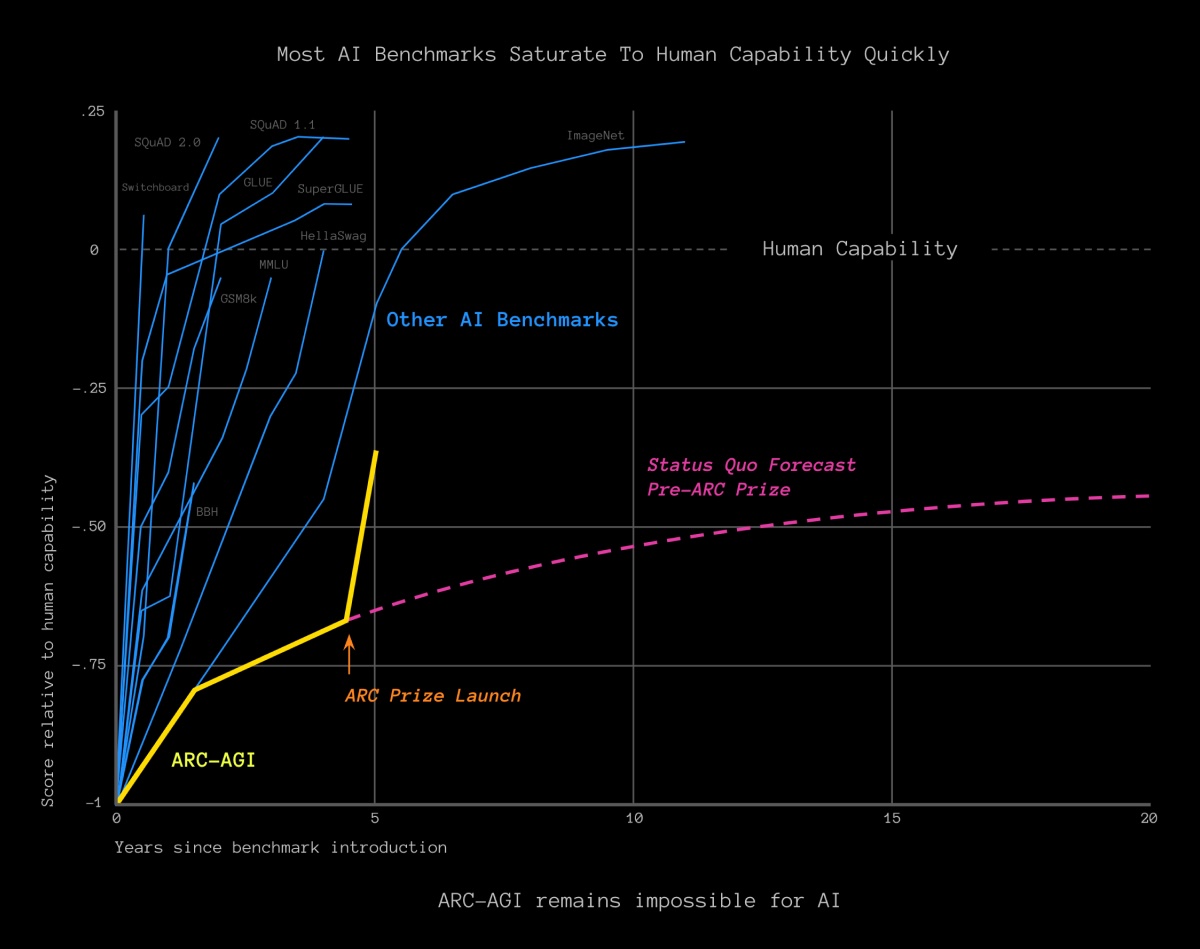
Benchmarks like SQuAD, HellaSwag, GLUE, and MMLU have been saturated very quickly when compared to ARC-AGI. This is another reason why o3 beating it is such a big deal. Image credit: 2
Here are some other benchmarks where o3 is performing very well:
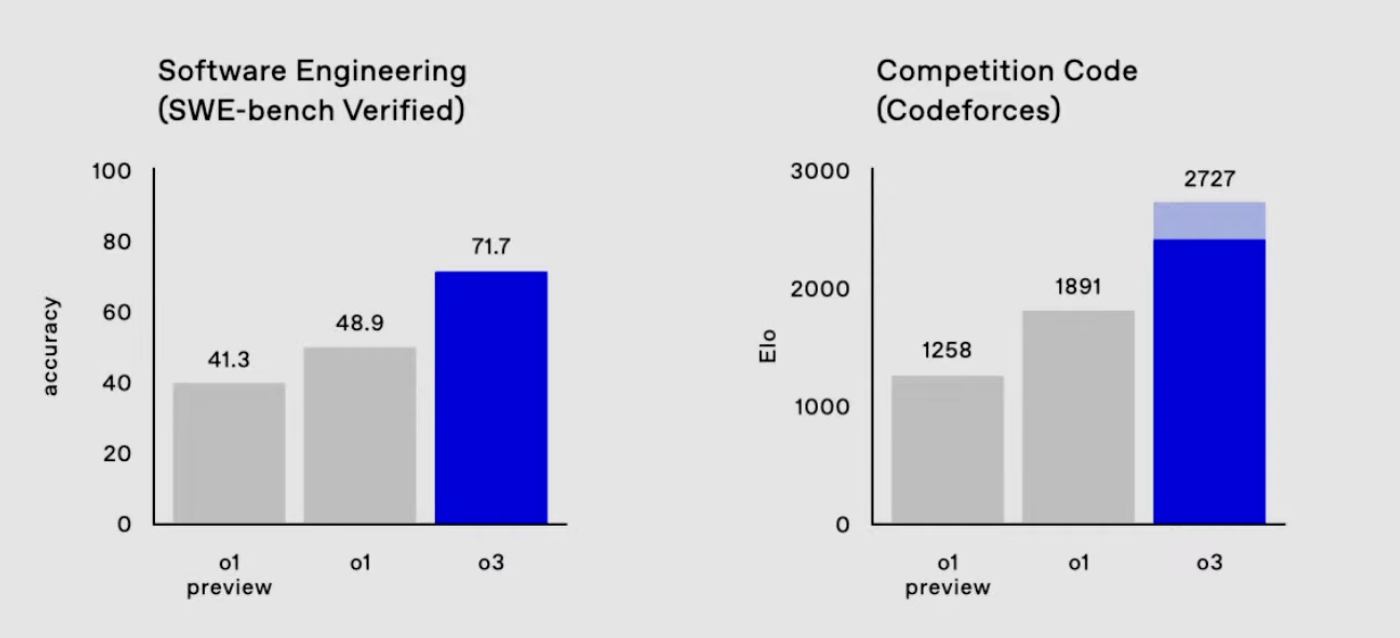
o3 achieves ~72% on the SWE benchmark and an Elo score of 2727. Image credit: 3
o3 achieves a whopping 97% on competition math and on PhD level science questions, it performs ~88%. Image credit: 3
Conclusion
The o3 system has also performed well on other benchmarks, including software engineering, competition code, maths, and PhD level science. However, as the ARC benchmark is particularly challenging, the o3 system's success on this benchmark is a testament to its capabilities. While the o3 system has not achieved AGI, its performance on the ARC benchmark has forced many to reconsider their views on the future of AGI.