Dense Retrievals: Bi-Encoders, Cross-Encoders, and Late Interaction
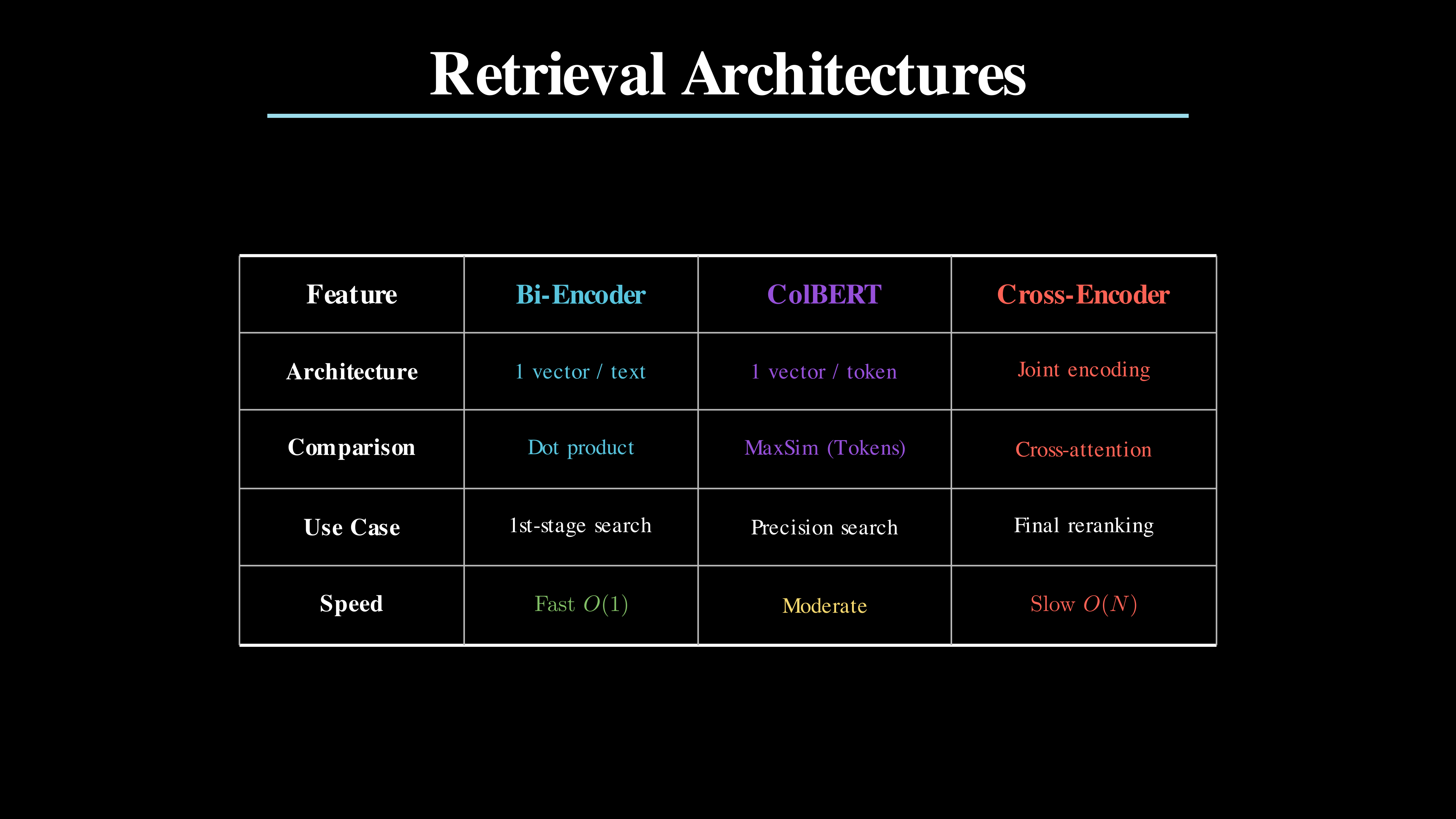
Table of Contents
Dense Retrievals: Bi-Encoders, Cross-Encoders, and Late Interaction
When it comes to dense retrieval, there is a fundamental tradeoff between speed and precision. You usually have to choose one. In modern search systems, your choice determines if your users get answers in milliseconds or if they get the 𝘳𝘪𝘨𝘩𝘵 answer at all. There are three main architectures for dense retrieval: bi-encoders, cross-encoders, and late interaction. Each has its own strengths and weaknesses.
Bi-Encoders (Dense Retrieval)
This is usually the one everyone starts with and is the most familiar with. Bi-encoders process your query and document separately. The model compresses text into a single vector. You calculate similarity with a dot product.
You can pre-compute document vectors and store them. This makes the search extremely fast. Use this to search millions of documents in milliseconds. However, do note that you lose word-level detail in the compression. You might miss specific names or numbers.
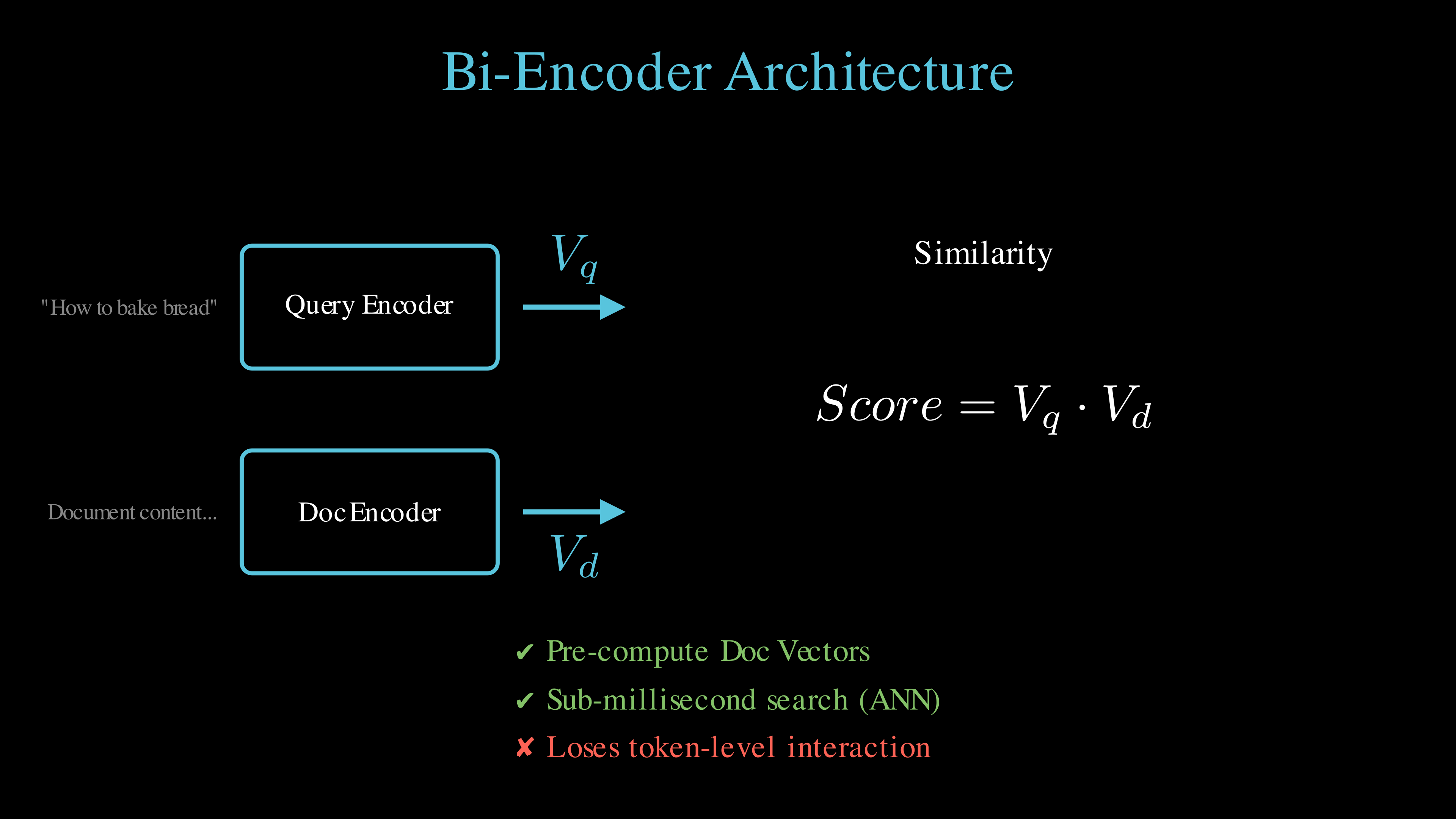
Bi-encoders process query and document independently, compressing them into single vectors for fast similarity search.
Cross-Encoders
Cross-encoders process your query and document together. The model uses full attention across both texts. Every token in your query interacts with every token in your document. This means that you get the most precise relevance score. You can capture specific details and nuances. However, you cannot pre-compute document vectors.
It is also the slowest. You must run the model for every document you want to compare. This is not feasible for large collections. You can only use this for re-ranking a small set of candidates.

Cross-encoders process query and document together, allowing for full token-to-token attention and higher precision.
Late Interaction (ColBERT)
Late interaction (like ColBERT) offers a middle ground. The model creates one vector for every token. It then finds the best match for each query token in the document using the MaxSim operator. In other words, you can write the score as:
You get token-level precision. You can still pre-compute document vectors. This makes ColBERT faster than cross-encoders. It is the sweet spot for high precision retrieval.
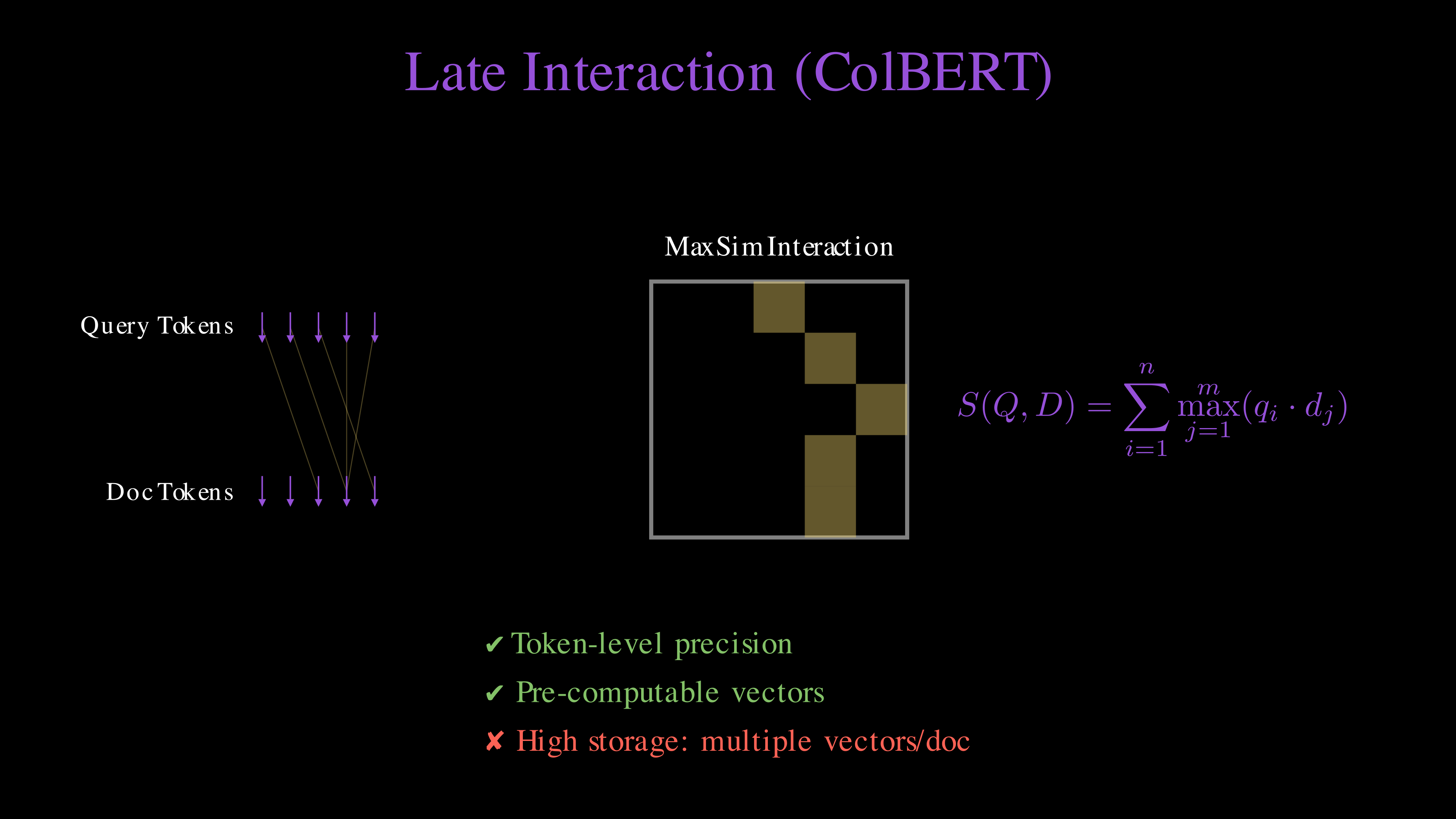
Late interaction (ColBERT) maintains token-level embeddings and uses the MaxSim operator for a balance of precision and scalability.
Comparison Summary
| Feature | Bi-Encoder | ColBERT (Late Interaction) | Cross-Encoder |
|---|---|---|---|
| Architecture | Compresses the entire text into a single dense vector representation. | Generates one vector per token, preserving fine-grained local information. | Performs joint encoding of the query and document together in one pass. |
| Comparison | Efficiently computes similarity using a simple dot product or cosine similarity. | Uses the MaxSim operator to find the best-matching document token for each query token. | Employs full cross-attention to let every query token interact with every document token. |
| Use Case | Ideal for first-stage retrieval across millions of documents in a vector database. | Perfect for high-precision search where you need a balance of speed and accuracy. | Best reserved for final re-ranking of a small candidate pool (e.g., top 10-50). |
| Speed | Extremely Fast ; similarity is computed in microseconds via ANN search. | Moderate; requires more computation than bi-encoders but is much faster than cross-encoders. | Very Slow ; must run the full transformer for every document pair. |
Bottom Line
Modern systems combine all three (or two) in a funnel.
- Use bi-encoders to find the top x candidates.
- Use ColBERT to narrow them down to the top y.
- Use cross-encoders for your final top z ranking.
You usually need to fine-tune the numbers (x, y, z) based on your latency requirements and the size of your document collection.
Most of the time, you also involve keyword search (sparse retrieval like BM25) in the first stage to enrich the candidate pool. While dense vectors excel at capturing semantics and synonyms, keyword search is unmatched at finding exact matches for specific product IDs, technical terms, or rare names. By combining the two in a Hybrid Search setup (e.g., using Reciprocal Rank Fusion), you ensure that your system doesn't hallucinate a 'semantic' match when a user is looking for a very specific string.
The video shows how bi-encoders, cross-encoders, and late interaction work in a visual manner. You can see how the query and document interact in each architecture and the tradeoffs between speed and precision.